

问题背景问题特点可行方法数学形式及解释Chinese Restaurant Process
狄利克雷分布是一种“分布的分布” (a distribution on probability distribution) ,由两个参数  确定,即
确定,即 ,
,  是分布参数(concentration or scaling parameter),其值越大,分布越接近于均匀分布,其值越小,分布越concentrated。
是分布参数(concentration or scaling parameter),其值越大,分布越接近于均匀分布,其值越小,分布越concentrated。  是基分布(base distribution)。
是基分布(base distribution)。
我们可以通过图1来形象的理解DP,可以把DP想象成黑箱,输入分布  ,输出分布
,输出分布  ,而
,而  控制输出的样子。
控制输出的样子。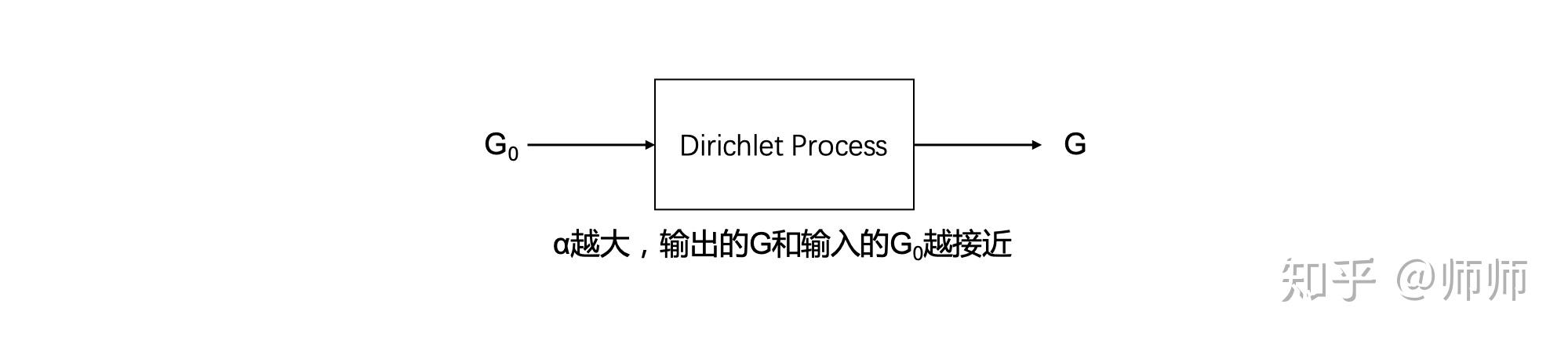 图1 理解DP分布与DP过程
图1 理解DP分布与DP过程
问题背景
我们有一组来源于混合高斯分布的数据集,希望对其进行聚类,然而我们并不知道这组数据是由几组高斯分布生成的(图1)。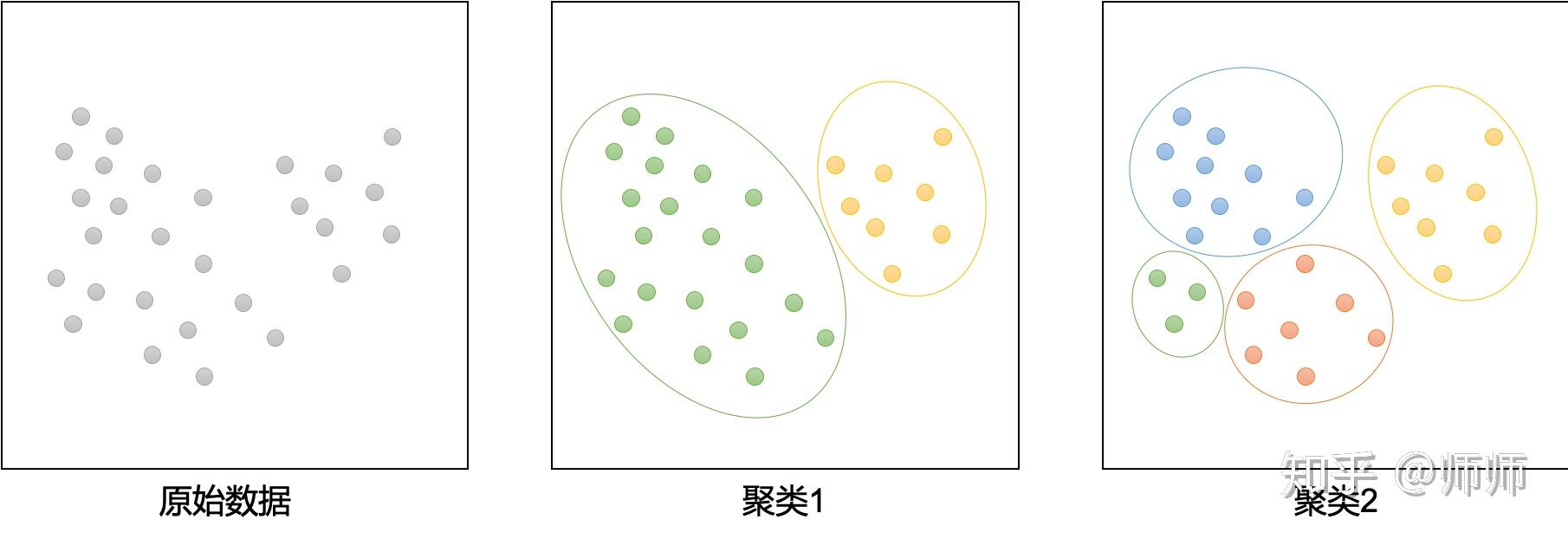 图1
图1
问题特点
(1)聚类数量未知
(2)非参数化,即不确定参数,如果需要,参数数量可以变化
(3)聚类数量服从概率分布
可行方法
针对高斯混合模型(Gaussian Mixture Models)做最大期望运算(Expectation Maximization, EM),分析结果,继续迭代计算。也可以做层次聚类(Hierarchical Clustering),比如层次凝聚法(Hierarchical Agglomerative Clustering, HAC),再进行人为剪枝。
然而,我们最希望的还是用一种以统计学为主,尽量避免主管因素(比如人为规定类别数量,人为进行剪枝)的方法来对数据进行聚类。
数学形式及解释
令Dirichlet Distribution为  ,其中
,其中 , > 0
, > 0
密度方程为  ,该分布中的样本
,该分布中的样本  在m-1维的概率单纯形中(probability simplex)中,即
在m-1维的概率单纯形中(probability simplex)中,即  是一个概率单纯形(图2)。
是一个概率单纯形(图2)。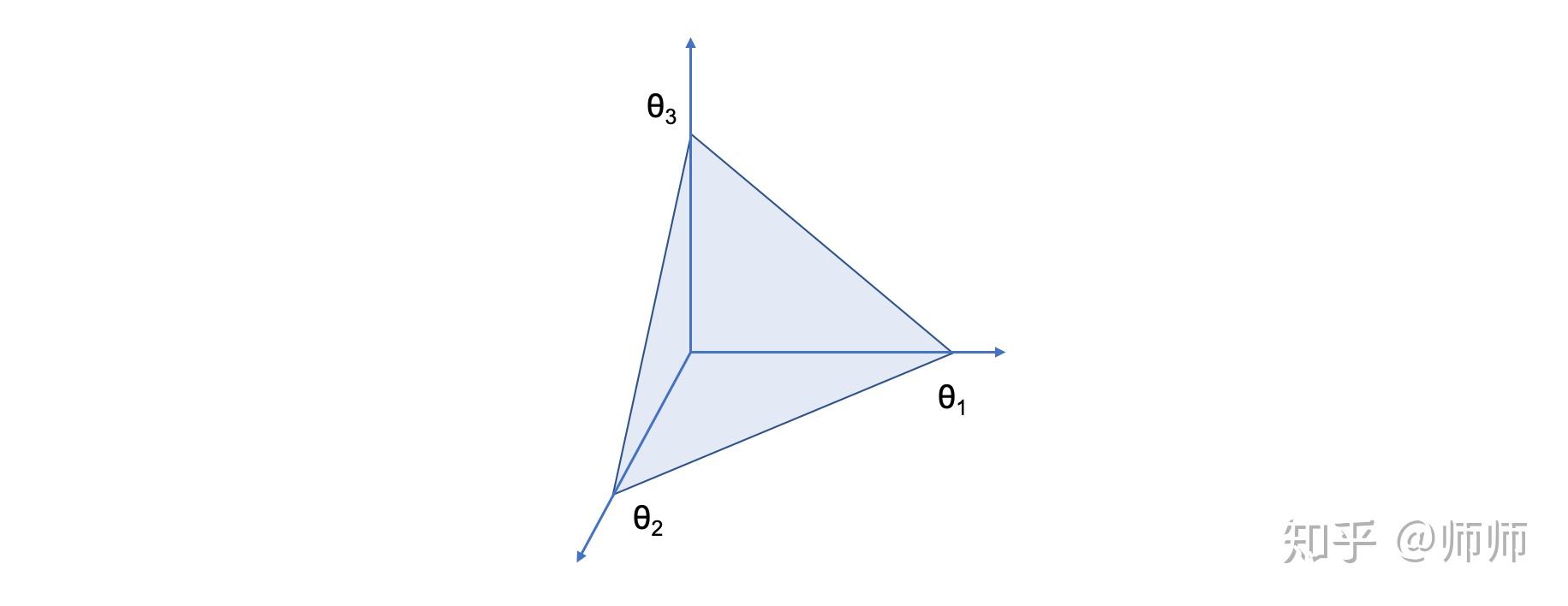 图2
图2
G服从于DP分布, ,其中 是正比例参数, 是base分布, 是随机概率测度,与具有相同的支持度。
狄利克雷过程的性质期望值与基分布相同:  随着
随着 
举例:假如 是高斯分布,那么,如图2。其中 是连续的,任意两个样本相同的可能性为0。而 是离散的,由有限且可数的点组成,任意两个样本相同的概率非零。 图2
图2
高斯混合模型,即Gaussian Mixture Models (GMM),是一种概率模型(不同于K-means)。
The Chinese Restaurant Process (CRP)
DP的后验分布是CRP
直观理解:当你参加一个大型聚餐时,往往想去一桌人多的地方,也就是“聚集效应”;而自己去一张新的桌子的概率取决于“心情”(,比如可能要帮别人占位置,那么 较大,占新桌子的可能性也更大)
数学理解:

其中  代表第n个饭桌上的人数。从上面的条件概率分布可以看出,新来的人更容易去人数多的桌子,也会有一定概率(由 决定)去新的桌子。
代表第n个饭桌上的人数。从上面的条件概率分布可以看出,新来的人更容易去人数多的桌子,也会有一定概率(由 决定)去新的桌子。
实际计算过程:将所有样本随机分配到初始聚类中在每次迭代  中:
中:
2.1 拿出一个样本
2.2 根据上述概率分布,为这个样本选择一个新的聚类
Toy Example:
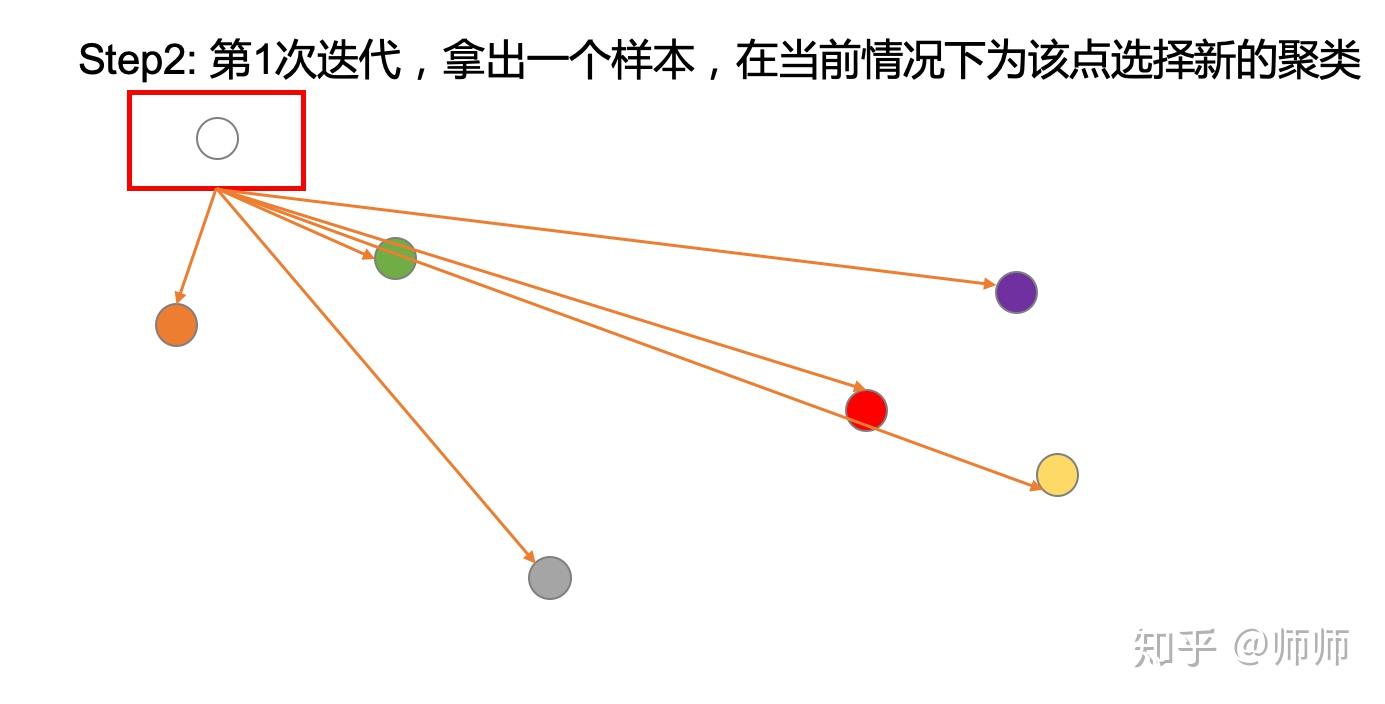
计算该点与其他6个点分别为同类别的概率 
计算该点为新聚类的概率 
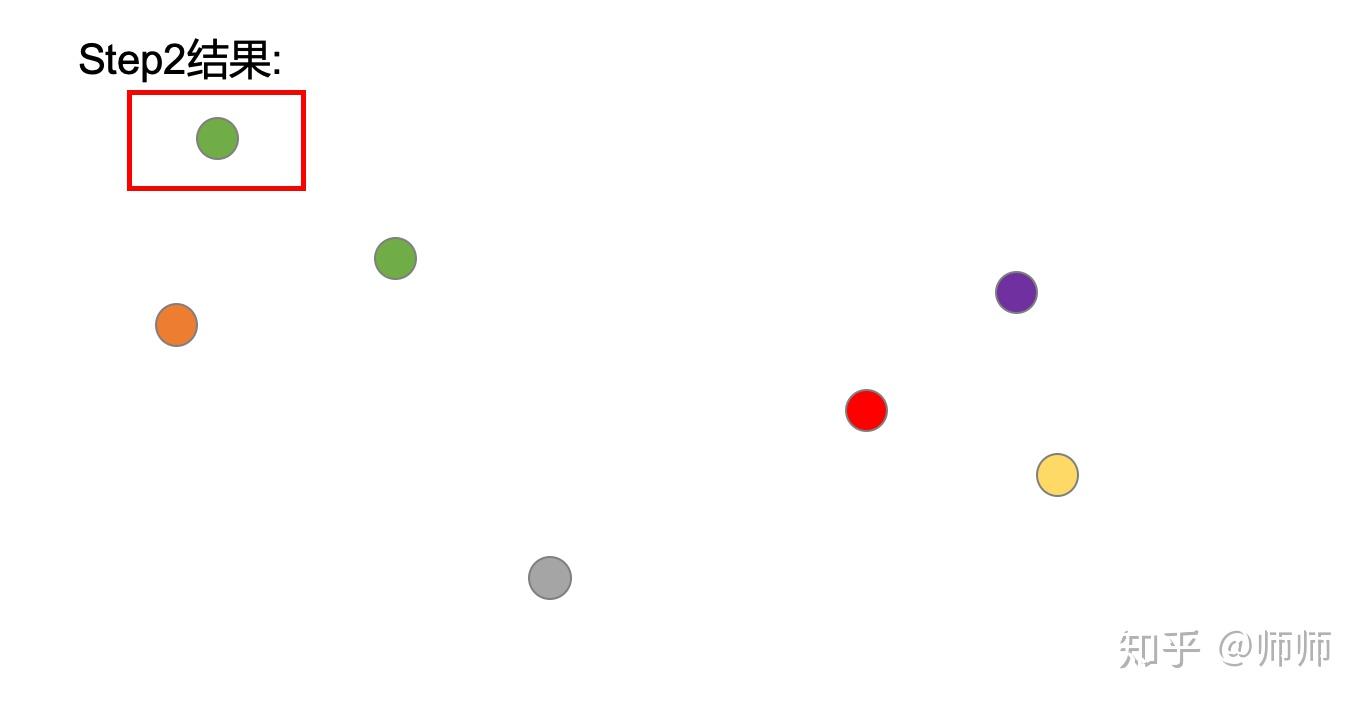
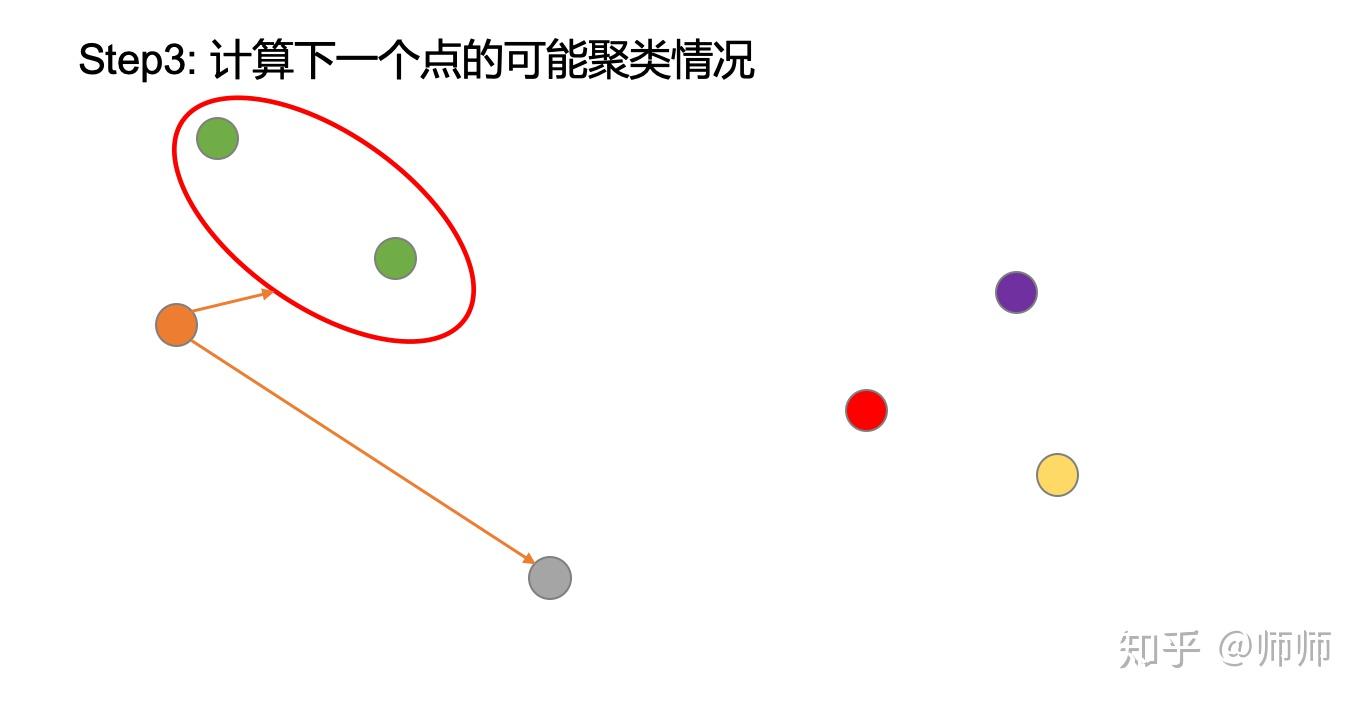
计算该点成为草绿色类别中一员的概率 
计算该点与其他点为同一类别的概率
计算该点为新聚类的概率 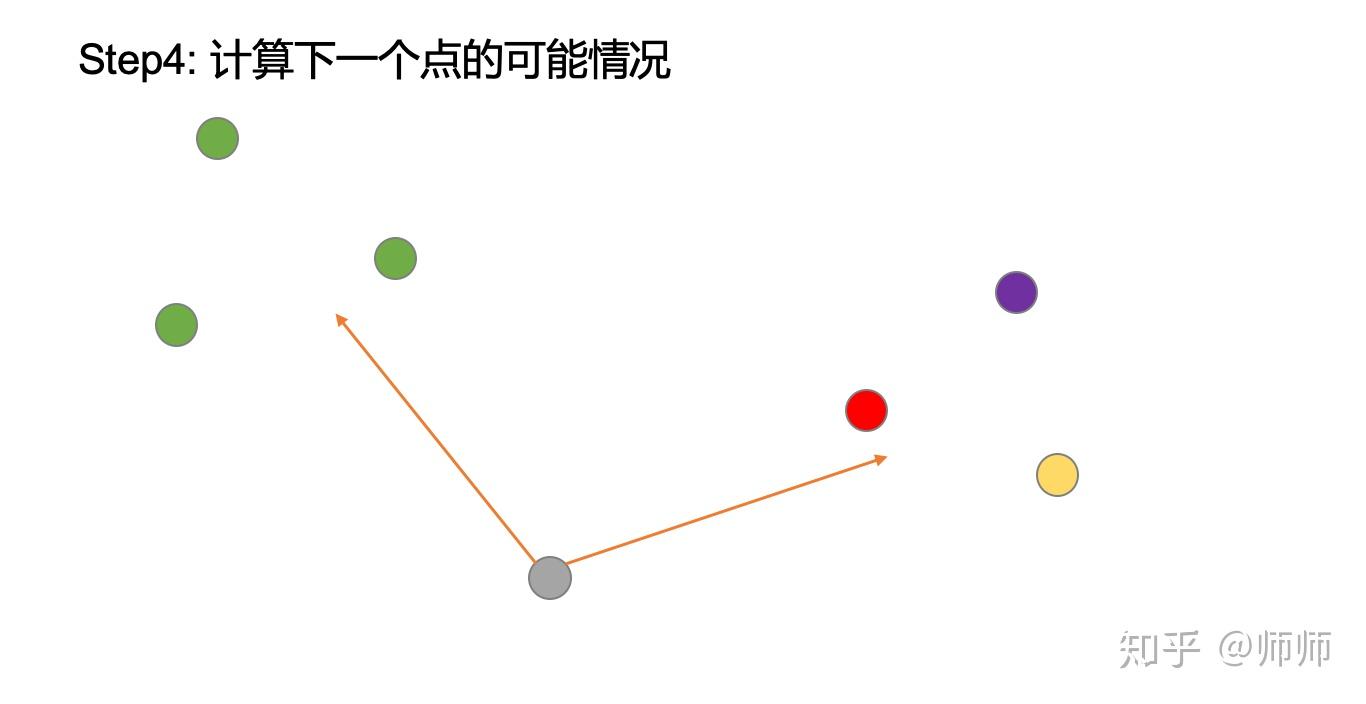
如果新类别的概率更大,则该点则会成为新的类别,这样的迭代计算继续进行下去,最终的结果如下:
(省略Step5, Step6)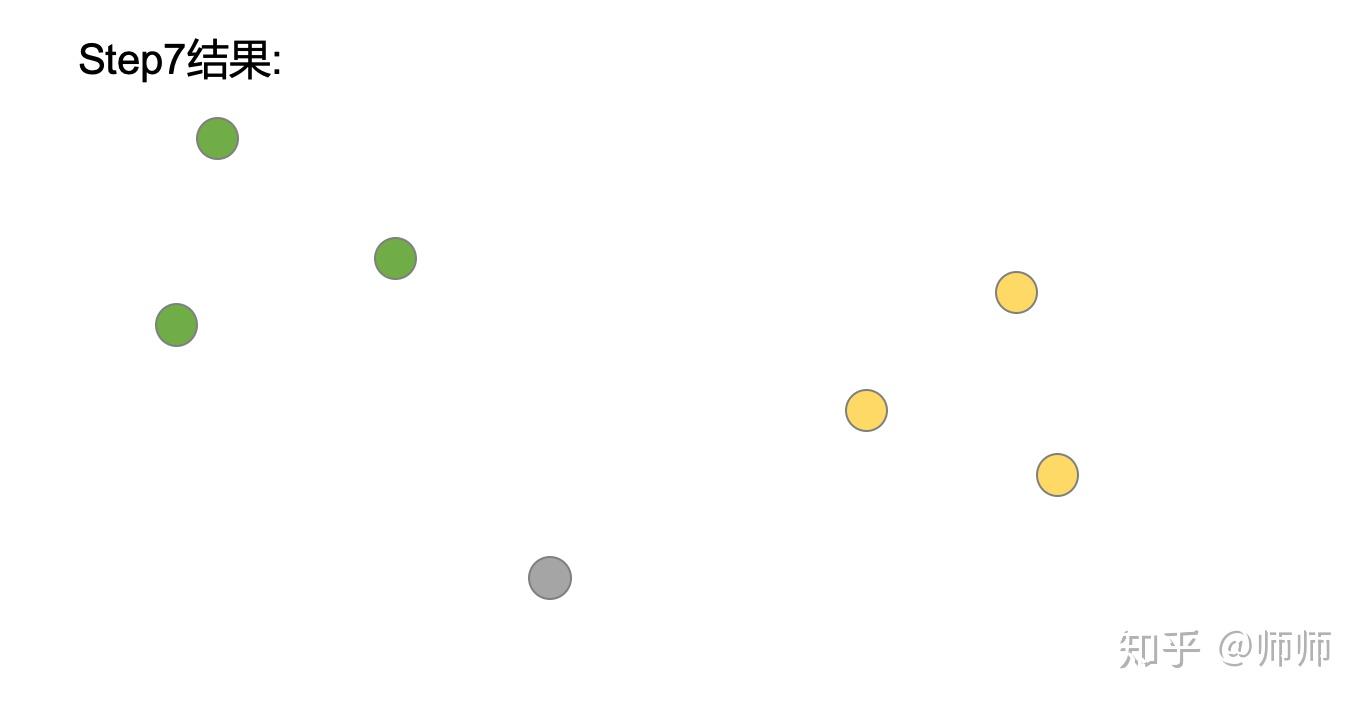
参考资料:一个很清楚的视频教程:https://www.youtube.com/watch?v=UTW530-QVxo一个很不错的课件:https://www.cs.cmu.edu/~kbe/dp_tutorial.pdf


文章声明:以上内容(如有图片或视频在内)除非注明,否则均为原创文章,转载或复制请以超链接形式并注明出处。
本文作者:admin本文链接:https://ywyvy.com/post/1476.html
还没有评论,来说两句吧...